
Grep in Flux Language for InfluxDB 2+
Queries built with the query builder are inflexible. See here gow to make them more adaptive.


I'm collecting various data from my house's KNX system (temperature, switches and so on). Initially, I had it collected in a MySQL database but, since this is a time series data and it's only interesting for statistics, I've decided to use InfluxDB. My measurements include the data type (DPT 9.001), name, description... as tags.
Initially, I used InfluxDB's query builder to select the fields:
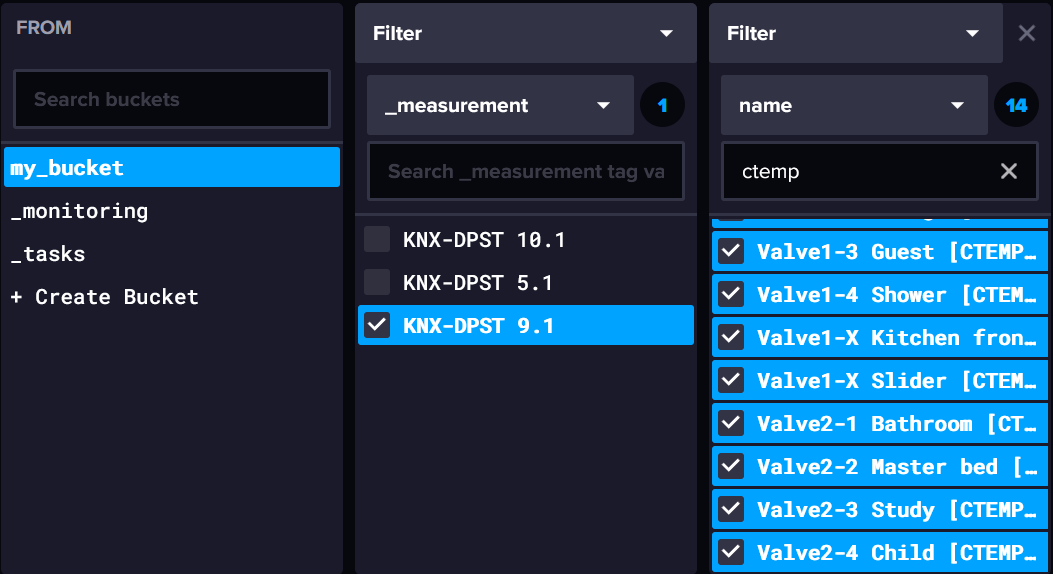
The results are OK:
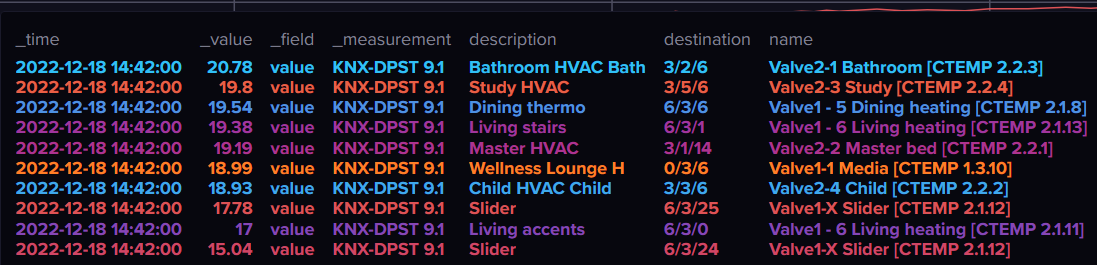
The query though is not at all elegant, not flexible:
from(bucket: "my_bucket")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "KNX-DPST 9.1")
|> filter(fn: (r) => r["name"] == "Valve1 - 5 Dining heating [CTEMP 2.1.8]" or r["name"] == "Valve1 - 6 Living heating [CTEMP 2.1.10]" or r["name"] == "Valve1 - 6 Living heating [CTEMP 2.1.11]" or r["name"] == "Valve1 - 6 Living heating [CTEMP 2.1.13]" or r["name"] == "Valve1-1 Media [CTEMP 1.3.10]" or r["name"] == "Valve1-2 Lounge [CTEMP 2.3.1]" or r["name"] == "Valve1-3 Guest [CTEMP 2.1.1]" or r["name"] == "Valve1-4 Shower [CTEMP 2.1.7]" or r["name"] == "Valve1-X Kitchen front [CTEMP 2.1.14]" or r["name"] == "Valve1-X Slider [CTEMP 2.1.12]" or r["name"] == "Valve2-1 Bathroom [CTEMP 2.2.3]" or r["name"] == "Valve2-2 Master bed [CTEMP 2.2.1]" or r["name"] == "Valve2-3 Study [CTEMP 2.2.4]" or r["name"] == "Valve2-4 Child [CTEMP 2.2.2]")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> yield(name: "mean")
As you can see, I'd have to change the query every time when I add a new temperature measurement (all switches I have in the house have temperature sensors!).
Enhancing the query
I remember that SQL has a string matching function, so I figured flux language must also have one. It does so, via strings.containsStr. I can then do something like this:
|> filter(fn: (r) => strings.containsStr(v: r["name"], substr: "CTEMP"))
... and all my CTEMP (current temperature) measures are collected automatically.
Final Query
The final query I have is:
import "strings"
from(bucket: "my_bucket")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "KNX-DPST 9.1")
|> filter(fn: (r) => strings.containsStr(v: r["name"], substr: "CTEMP"))
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> yield(name: "mean")
This gives me something like:
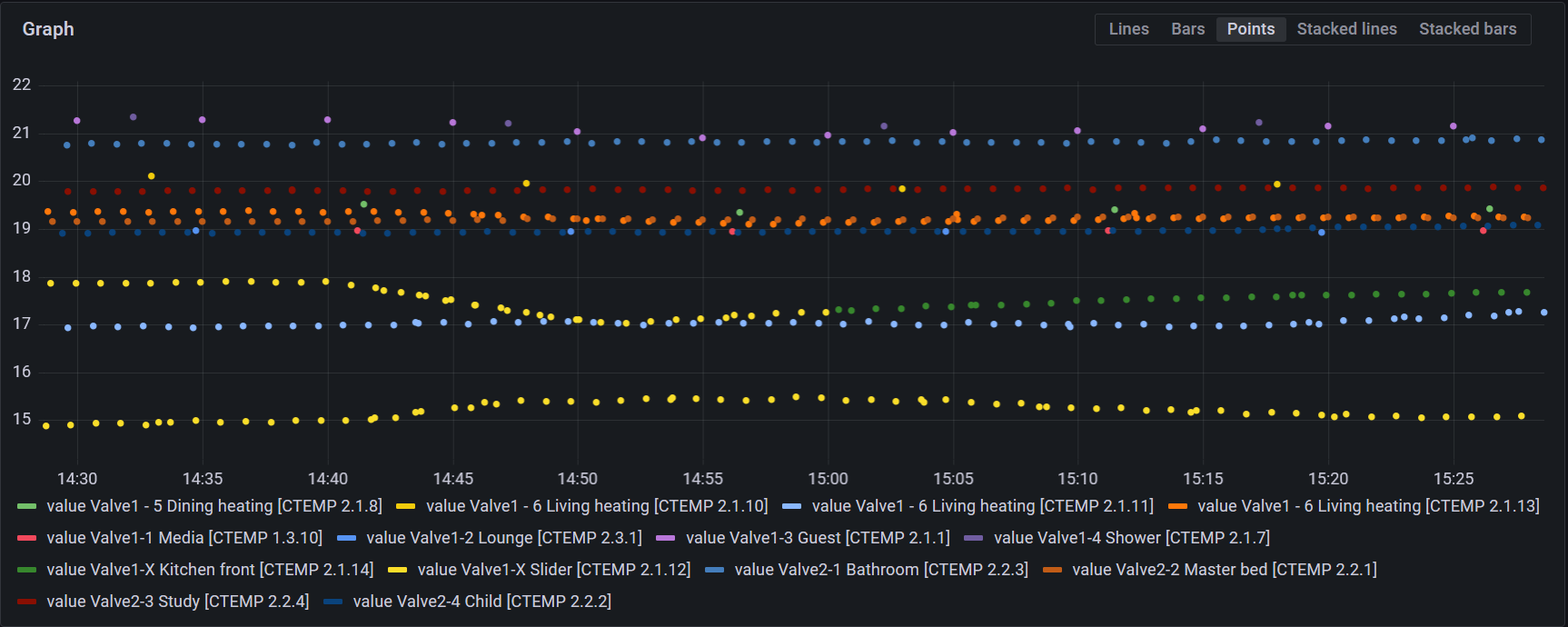
You can see the update I did in hte middle of the graph (yellow dots to green) where I had a typo in the description and I've fixed it.
HTH,